Zookeeper概述
在分布式系统之中,集群各个机器的协同工作是一个比较难解决的点。对此ZooKeeper应运而生,开发者可以通过ZooKeeper来实现一些分布式一致性服务。同样的,Zookeeper也可以是一个集群,但是ZooKeeper集群之中的细节可以被很好的隐藏。这样说会有些抽象,可以用示意图简单地描述ZooKeeper的集群架构,其示意图如下:
一个ZooKeeper集群内有一个Leader(领导者)和众多的follower(追随者),Leader和Follower之间可以相互通信。这种组织形式与MySQL和Redis的集群组织形式比较类似。不妨来了解一下ZK集群的一些特点。其特点如下:
- Zookeeper集群服务正常运行的前提是集群之中有一半以上的节点存活。
- 每一个节点服务器中,都保存着同样的数据副本。
- 来自同一个Client的更新请求将会按照顺序执行,这一点有点像队列。
- 数据更新有类似事务的原子性。
但是值得注意的是,集群服务器在同一时间一直保持数据一致性是实现起来非常困难的,所以这里的节点保持的数据一致性,是在一定时间范围之内而言的。前面说到,ZK集群的细节可以被很好的隐藏,是因为我们所开发的程序可以作为一个Client连接到集群之中的任意一台服务器,就可以不考虑其他的细节而完成我们的业务逻辑。
了解了ZK的集群,可以再继续深入一些,了解ZK的数据结构。ZK的数据结构是一个树,其组织形式类似于Unix的目录结构。其目录结构的示意图如下:
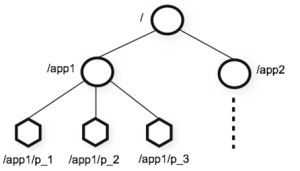
来看看官方文档中的描述:Unlike standard file systems, each node in a ZooKeeper namespace can have data associated with it as well as children. It is like having a file-system that allows a file to also be a directory.
这段话翻译过来大概的意思是,ZK的数据结构类似一个文件系统但是与标准的文件系统是不同的,因为ZK的每一个Znode节点都可以存储数据,也可以记录当前节点与子节点的关联关系。
Znode的生存时间取决于创建这个Znode的会话,如果会话是active的那么Znode节点也将会存在,如果会话结束了,Zonde节点也就被删除。Znode节点可以维护一个版本号,每次数据更新的同时,节点数据的版本号也会随之更新。假设我有一个Client从Znode节点获取数据,那么Client也会同时收到这个数据的版本号。
- Zookeeper的应用场景
Zookeeper可以为分布式集群提供如下的服务:统一命名服务、统一配置服务、统一集群管理、服务器节点动态上下线和软负载均衡等。
- 统一命名服务
通过树形节点结构(类似文件系统目录)为资源分配唯一路径名,如 /services/serviceA,确保名称全局不重复。在建立了节点时候,在节点中存储服务的信息,例如IP等等。这类似于域名服务器内存储着域名对应的IP地址。
- 统一配置服务
有的时候集群需要同步配置文件,这也可以通过ZK来实现。我们可以将配置文件序列化之后,存入Znode中。同时其他的Client都监听这一个Znode节点,因此可以对Znode节点进行响应。一旦Znode中的数据被修改了,Zk服务将会通知各个Client。
- 统一集群管理
可以使用Zookeeper来管理集群,监控节点的状态变化。监控Znode可以实时获取其状态的最新变化。
- 服务器节点动态上下线
检测集群机器的加入和退出,我们可以约定一个目录,所有的集群信息节点都作为这个目录下的子节点添加。随后可以监视子节点的变化情况。如果有机器退出,该机器的会话结束,那么其对应的Znode也会被删除;反之如果有机器加入,则会创建新的Znode节点。
- 软负载均衡
可以在Zookeeper里面记录服务器的访问数量,再让访问数量最小的服务器去处理客户端的请求。